Accelerator I/O connectors and cables provide secure, electrical contact and transmission for high-speed data. These devices typically make up one of the largest unit percentages of data-center equipment in terms of use and assembly. This is particularly true compared to top-of-rack (TOR) switching fabric network interface cables, such as Ethernet or InfiniBand.
TOR switching is a data-center architecture design whereby computing equipment (such as servers or switches) are placed within the same rack and are connected to an in-rack network switch. This type of architecture typically places a network fiber switch in every rack to connect more easily with every other device in the rack.

In hyperscale data-center systems, however, accelerator interfaces offer more options. They run eight to 16 lane-cabled links. In comparison, Ethernet is usually a QSFP (four-lane quad, small form-factor pluggable) cable. It’s been the primary type of high-speed IO interface interconnect until now.
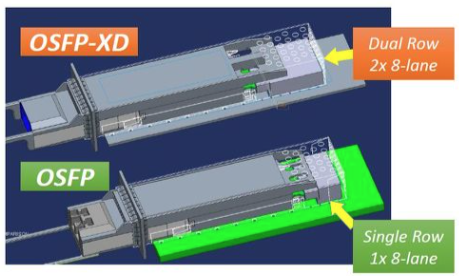
Accelerator devices are driving new possibilities, such as eight-lane QSFP-DD, OSFP (octal small-form-factor pluggable), 16-lane double-stack QSFP-DD, and OSFP-XD interconnects — including the connectors, cables, as well as module active Ethernet and active optical cables.
There are now more options. For instance, by using at least four cable legs and two QSFP-DD plugs in a single cable assembly, and then plugging it into a double-stack QSFP-DD receptacle, it’s now possible to devise a 1.6T-link, 1m passive or 2m active DAC solution. Granted, using the OSFP-XD is still more feasible because it offers better thermal performance, faceplate port density, and a lower channel operating budget.
There are few full, high-speed interconnect product suppliers that can afford to test, stimulate, source, and build the 112+G per-lane assemblies and components due to the cost and limited supply chains.
GPU accelerators — such as NVidia’s NVLink 3.0, AMD’s Instinct MI200, and Intel’s Ponte Vecchio 2.0 — appear to favor using the standard pluggable interconnects, internal 112G PAM4 per-lane types, and fewer proprietary connectors and cables (at least compared to earlier designs). They’re mostly using eight and 16-lane implementations.
These systems, which consist of several GPU 1U and 2U boxes of accelerator blades and switches are connected on a single rack. The racks are typically connected by external cables and the boxes are employing newer, internal cables and connectors.
System accelerators — such as AMD’s Infinity Fabric, IBM’s BlueLink, NVidia’s Bluefield, HPE’s Slingshot, and the EU’s EPI Rhea — typically use eight, 16, and 32+ lane links. However, customized cabling solutions that support the ideal system fabric network do exist. A unique implementation of BlueLink included 96 lanes. But these IO interfaces tend to be eight lanes, using a pluggable series of interconnects.
Memory storage accelerators — such as the latest versions of OpenCAPI, Open Memory Interface, CXL, GenZ, and custom CCIX are using eight and 16 lanes, internally — inside the box and inside the rack of external cables and connectors. Often internal Twinax, pluggable jump-over cables that connect to faceplates and external pluggable connectors and cables are used. Internal-only applications can use the standard options or one of the newer, proprietary 112G cables and connectors, such as Samtec’s NovaStack seen here…

The OCP’s Accelerator Module development spec, which defines the form factor and common specifications for a compute accelerator module and a compliant board design, accepts the use of the SFF-TA-1020 internal I/O connectors and cables. This is also true of the Open Compute Project (OCP) NIC 3.0 specification, as seen in Intel’s new Ice Lake CPU-based applications.
However, some applications will continue to rely on the SFF-TA-1016 interconnects, which are rated for 106 and 112G per-lane link budget requirements.

It also seems that the new, Smart Data Accelerator Interface SDXI memory-to-memory switching links use internal Twinax cables with SFF-1020 or SFF-1016 connectors (also called MCIO types).
Additionally, the PCB paddleboard plug R/A, VT, Orthogonal straddle-mount options are possible if using 0.6mm-pitch, SFF-TA-1020 connectors. There are options.
Cable accelerators
An overall preference for accelerator links, especially in large hyperscale data centers, has led to an increase in the use of active chips embedded in cable plugs. These chips use different technology and can function as equalizers, re-timers, signal conditioners, and gearboxes.
Originally, an active type of DAC cable was supported by several IO interfaces with similar speed rates, but now they’re offered as 112G PAM4 per-lane active copper cable or ACC.
More recently, a 106G per-lane active Ethernet cable product has launched and is referred to as AEC by its chip developer. This chip supports several Ethernet data rates. Another company also recently developed Smart Plug modules with a chipset for use in 112G per-lane PAM4 active electronic cable — or AEC. The acronyms are the same, so be aware of the context.
A few other companies are offering 106 or 112G options. Spectra-7 has a new 112G PAM4 per-lane linear equalizer, dual-channel chip, which supports top or bottom-mounting and routing embedded in SFP, SFP-DD DSFP, QSFP, QSFP-DD, and OSFP cable plugs. Several leading cable assembly companies currently use the Spectra 7 embedded chips.
Cameo offers 112G PAM4 re-timers and gearbox chips, embedded in their own active cable assembly product family.
Astera Labs has developed a new, 106G PAM4 per re-timer chip with advanced fleet management and deep diagnostic functions. This chip supports multiple Ethernet speed rates.
When choosing the ideal option, system engineers must consider the available power, cable-routing options, cooling costs, form fact, topologies, and overall cost for each chip type and ACC type.
OEMs and end-users typically dictate the use of a specific active chip and plug type, as well as the assembly configuration. Although typical cables can use 34 AWG, Twinax wire conductors, a 16-lane cable uses 64 wires that form a substantial bundle diameter.
Final thoughts
There are advanced 212 and 224G per-lane chips now in development to support short-reach copper links. Features include minimum power consumption and greater functionality, although the cost will be an important consideration.
It’s also important to compare CMIS, COM, IL, BER parameters and test data of the various accelerator connectors, cables, and PCBs. Inter-operability between these devices will be a key to supporting heterogeneous networks.
Many 112G PAM4 and most 224G PAM4 accelerator applications will require embedded, active copper chips that minimize the cable-bundle diameter. For small-bundle diameters and longer lengths, the use of eight-lane QSFP-DD, OSFP, and 16-lane QSFP-XD AOCs are the better options — and likely required for achieving 224G per-lane link reaches.
The 32+ lane Twinax cables work for internal applications but not for external cables. Multiple jacketed and shielded copper fan-out cable legs can quickly become cumbersome and costly. To date, the cost of competing AOCs is decreasing while that of AECs has remained steady.
Developers are wise to keep in mind that customers typically go for proven and value-added technology and performance that’s matched with a reliable supply chain.



