David Stratman and Vinay Patwardhan, Cadence
In the more complex world of today’s SoCs, you’re integrating a large number of third-party IP blocks with your own highly tuned RTL, while aggressively pushing frequency in the face of lower power requirements and area budgets. You also want to ensure a reliable handoff to place and route (P&R). In this article, we’ll discuss massively parallel RTL synthesis and physical synthesis techniques and technologies that can meet the challenges of designing advanced-node SoCs by:
- Supporting early power, performance, and area (PPA) optimization of the datapath microarchitecture
- Correlating tightly to place and route
- Boosting RTL design productivity to help you meet tight design schedules
Given how complex and large SoCs for high-end applications have grown, it’s more important than ever to solidify your design’s microarchitectures and begin RTL synthesis as early as possible. Not only that, it’s crucial to start the process right to ensure a reliable handoff to P&R for effective design closure. Otherwise, you face wasted iterations at P&R.
By bringing physical considerations into the logic synthesis flow much earlier in the process, you can solve some of these challenges. Physical synthesis enhances the design process significantly and reduces the amount of time spent fixing problems late in the flow. However, current physical synthesis technologies have limitations when it comes to complex, advanced-node SoCs.
For complex SoCs, you need to be able to better model all critical physical effects related to placement, routing, and clocking. Such a process could be streamlined by using common engines and shared assumptions with the implementation technologies used later in the flow. Additionally, to handle growing SoC design sizes, you need techniques that can speed up synthesis runtime and capacity in order to be at your most productive level.
The Minimum Needed for Better Physical Synthesis
To build your physical synthesis foundation, you do need a few capabilities that are available today to help you generate a better netlist structure:
- Using a physical floorplan reference for RTL synthesis optimization can create a good initial netlist for P&R to support a better timing/power/area balance
- The ability to structure your netlist to account for real wire delays and identify long wires allows synthesis to more effectively “squeeze” critical paths and “relax” non-critical paths, improving both correlation and timing
- Structuring and mapping techniques that consider the physical scope can help relieve routing congestion and total negative slack (TNS)
- Physical synthesis can help reduce total chip power and optimize design-for-test (DFT) logic
What Can You Do to Enhance Your Synthesis Flow?
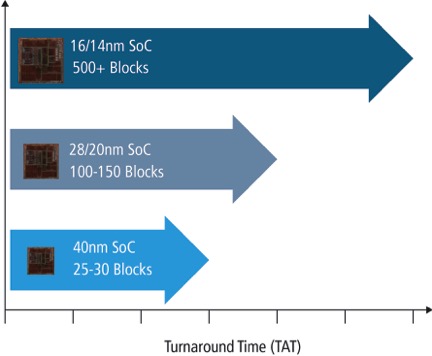
Limited capacity is one of the biggest hurdles for RTL synthesis of advanced-node SoCs. The massively parallel architecture trend has emerged as a viable solution. By tapping into a rapidly increasing number of processors in order to perform a set of coordinated functions concurrently, a massively parallel architecture can facilitate a much faster turnaround time, which results in improved RTL design productivity.
How the synthesis tool partitions the design, in concert with its massively parallel architecture, can also contribute to faster synthesis runtime. For example, imagine the productivity advantages if you could:
- Divide your design up into multiple partitions at a particular stage in the flow
- Run these partitions in parallel
- Merge the partitions back into the full chip
Taking this concept a step further, picture how much work you could get done if you could also break your entire design into multiple high-level partitions that are each taken through all stages of the design cycle.
Current synthesis tools already leverage parallelism in many places, but we see two key challenges limiting their ability to scale further without degrading PPA:
- The long pole effect: The number of gates is not a good measure of optimization runtime. Different parts of a design may require different amounts of optimization effort to achieve a good result. If partitioning is based only on gate count and not optimization effort, then some partitions can become the “long pole” and bottleneck of any runtime improvements.
- Design hierarchy: The best partitioning to eliminate the long pole effect may not align with module or physical hierarchies, so partitioning needs to be able to “slice” through design hierarchy without forcing ungrouping of that hierarchy.
What is now needed to make partitioning effective is the assurance that you won’t experience the typical QoR or PPA degradation that can occur when recombining or merging the partitions back together.
Mapping capabilities are another area of consideration. Existing technologies do account for timing and area while doing synthesis, but independently and iteratively. What if you could look at your design globally and examine more than one constraint concurrently?
With smaller designs at established processes, it hasn’t always been important for synthesis to consider downstream effects like congestion. But downstream effects are certainly important with larger, advanced-node designs. If the mapping function in your synthesis tool could analyze different constraints concurrently and with an accurate physical context, then you’d be better able to produce a netlist that holds up through P&R.
A next-generation synthesis tool
The new Cadence Genus Synthesis Solution, a next-generation RTL synthesis and physical synthesis tool, overcomes limitations of traditional synthesis tools with innovative algorithms that improve RTL designer productivity. Its scalable, massively parallel global analytical architecture accelerates turnaround time. Its global datapath optimization engine can greatly reduce datapath area and power consumption. The solution provides:
- Up to 5X faster synthesis runtime scalable to 10M+ instances
- Ultra-tight correlation to P&R through shared engines and algorithms
- Global analytical architecture-level early PPA optimization, with up to 20% reduction in datapath area and power
- 2X+ reduction in iterations between unit- and chip-level synthesis from a new physically aware context-generation capability
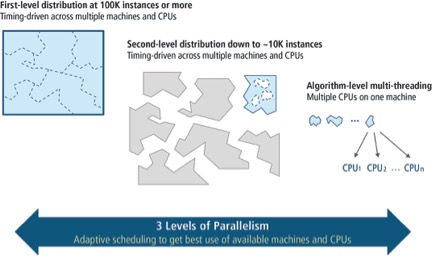
While manual design partitioning has become necessary with large, advanced-node designs, the approach is a drain on productivity and engineering resources. Adopting new massively parallel RTL synthesis and physical synthesis technologies can enhance your synthesis flows. Next-generation RTL synthesis and physical synthesis capabilities can help ensure that even the smallest unit-level circuits fully meet timing and power targets, while the largest SoC blocks can be synthesized quickly and accurately to generate a better correlated netlist and faster eventual tapeout.
Cadence, Inc.
www.cadence.com

Leave a Reply
You must be logged in to post a comment.