QUT researchers have developed a new way for robots to see the world from a more human perspective, which has the potential to improve how technology, such as driverless cars and industrial and mobile robots, operates and interacts with people.
In what is believed to be a world first, Ph.D. student Sourav Garg, Dr. Niko Suenderhauf and Professor Michael Milford from QUT’s Science and Engineering Faculty and Australian Centre for Robotic Vision, have used visual semantics to enable high-performance place recognition from opposing viewpoints.
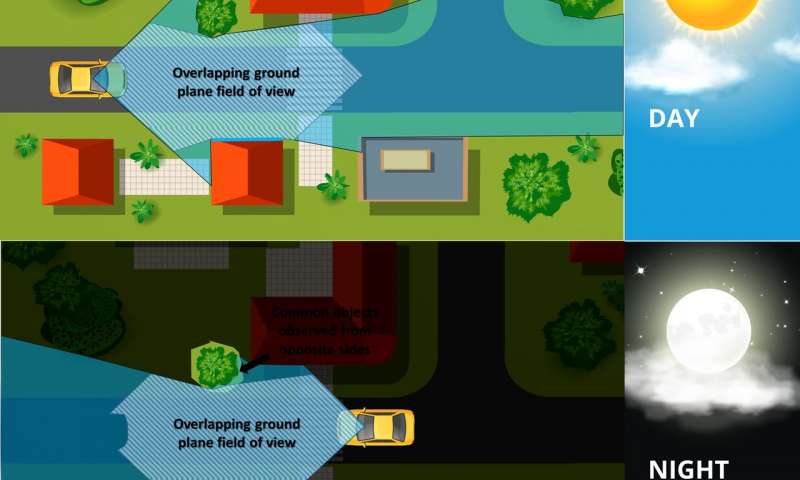
Mr Garg said, while humans had a remarkable ability to recognise a place when re-entering it from the opposite direction, including in circumstances where there are extreme variations in its appearance, the task had presented challenges for robots and autonomous vehicles.
“For example, if a person is driving down a road and they do a u-turn and head back down that same road, in the opposite direction, they have the ability to know where they are, based on that prior experience, because they recognise key aspects of the environment. People can also do that if they travel down the same road at night time, and then again during the day time, or during different seasons,” Mr Garg said.
“Unfortunately, it’s not so straightforward for robots. Current engineered solutions, such as those used by driverless cars, largely rely on panoramic cameras or 360 degree Light Detection and Ranging (LIDAR) sensing. While this is effective, it is very different to how humans naturally navigate.
Professor Michael Milford said the system proposed by the QUT team of researchers used a state-of-the-art semantic segmentation network, called RefineNet, trained on the Cityscapes Dataset, to form a Local Semantic Tensor (LoST) descriptor of images. This was then used to perform place recognition along with additional robotic vision techniques based on spatial layout verification checks and weighted keypoint matching.
“We wanted to replicate the process used by humans. Visual semantics works by not just sensing, but understanding where key objects are in the environment, and this allows for greater predictability in the actions that follow,” Professor Milford said.
“Our approach enables us to match places from opposing viewpoints with little common visual overlap and across day-night cycles. We are now extending this work to handle both opposing viewpoints and lateral viewpoint change, which occurs, for example, when a vehicle changes lanes. This adds an extra degree of difficulty.”
