The ability to run neural networks (NNs) on MCUs is growing in importance to support artificial intelligence (AI) and machine learning (ML) in the Internet of Things (IoT) nodes and other embedded edge applications. Unfortunately, running NNs on MCUs is challenging due to the relatively small memory capacities of most MCUs. This FAQ details the memory challenges of running NNs on MCUs and looks at possible system-level solutions. It then presents recently announced MCUs with embedded NN accelerators. It closes by looking at how the Glow machine learning compiler for NNs can help reduce memory requirements.
Running NNs on MCUs (sometimes called tinyML) offers advantages over sending raw data to the cloud for analysis and action. Those advantages include the ability to tolerate poor or even no network connectivity and safeguard data privacy and security. MCU memory capacities are often limited to the main memory of hundreds of KB of SRAM, often less, and byte-addressable Flash of no more than a few MBs for read-only data.
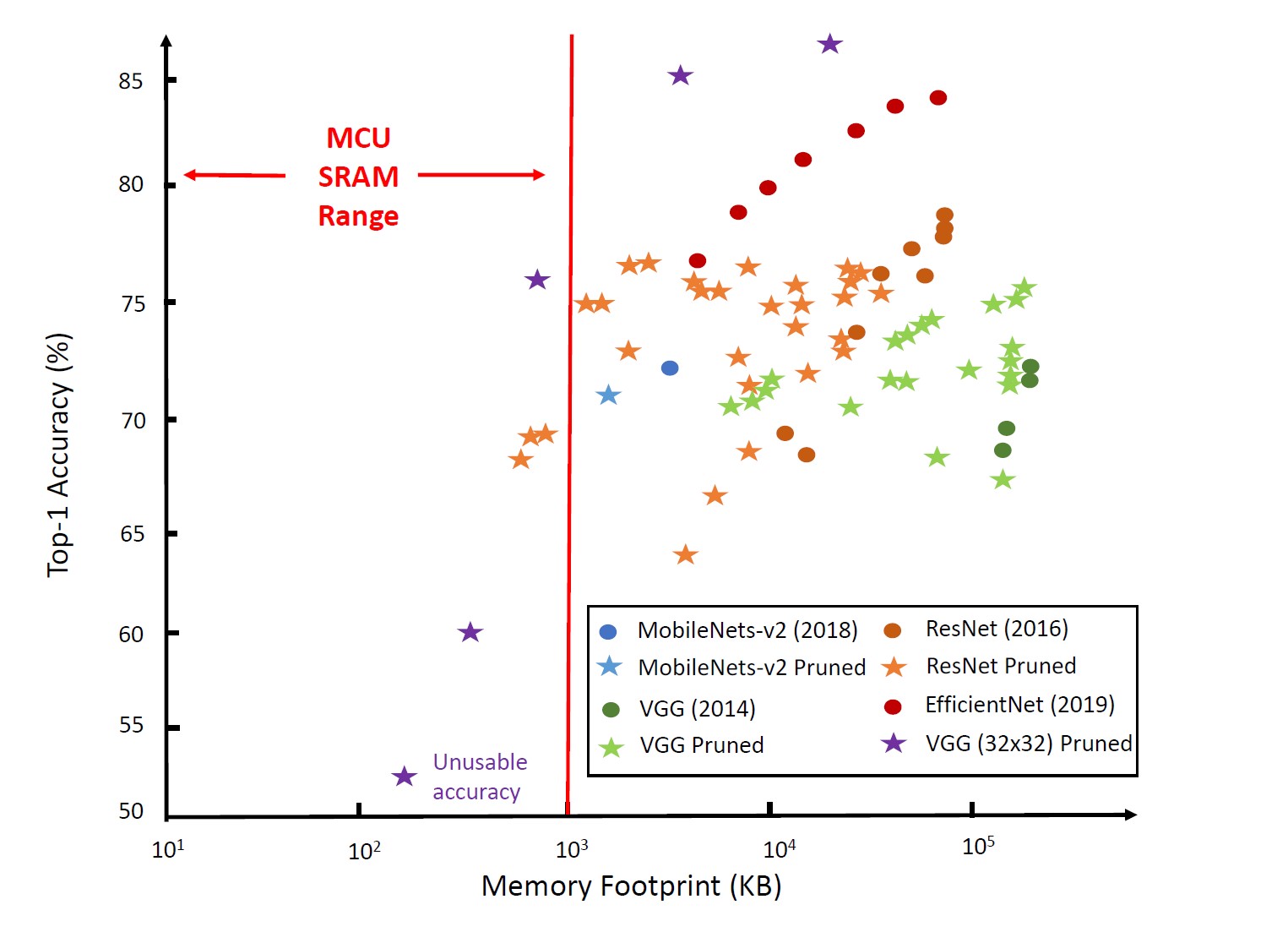
To achieve high accuracy, most NNs require larger memory capacities. The memory needed by a NN includes read-only parameters and so-called feature maps that contain intermediate and final results. It can be tempting to process an NN layer on an MCU in the embedded memory before loading the next layer, but it’s often impractical. A single NN layer’s parameters and feature maps can require up to 100 MB of storage, exceeding the MCU memory size by as much as two orders of magnitude. Recently developed NNs with higher accuracies require even more memory, resulting in a widening gap between the available memory on most MCUs and the memory requirements of NNs (Figure 1).
One solution to address MCU memory limitations is to dynamically swap NN data blocks between the MCU SRAM and a larger external (out-of-core) cash memory. Out-of-core NN implementations can suffer from several limitations, including: execution slowdown, storage wear out, higher energy consumption, and data security. If these concerns can be adequately addressed in a specific application, an MCU can be used to run large NNs with full accuracy and generality.
One approach to out-of-core NN implementation is to split one NN layer into a series of tiles small enough to fit into the MCU memory. This approach has been successfully applied to NN systems on servers where the NN tiles are swapped between the CPU/GPU memory and the server’s memory. Most embedded systems don’t have access to the large memory spaces available on servers. Using memory swapping approaches with MCUs can run into problems using a relatively small external SRAM or an SD card, such as lower SD card durability and reliability, slower execution due to I/O operations, higher energy consumption, and safety and security of out-of-core NN data storage.
Another approach to overcoming MCU memory limitations is optimizing the NN more completely using techniques such as model compression, parameter quantization, and designing tiny NNs from scratch. These approaches involve varying tradeoffs between model accuracy and generality, or both. In most cases, the techniques used to fit an NN into the memory space of an MCU result in the NN becoming too inaccurate (< 60% accuracy) or too specialized and not generalized enough (the NN can only detect a few object classes). These challenges can disqualify the use of MCUs where NNs with high accuracy and generality are needed, even if inference delays can be tolerated, such as:
- NN inference on slowly changing signals such as monitoring crop health by analyzing hourly photos or traffic patterns by analyzing video frames taken every 20-30 minutes
- Profiling NNs on the device by occasionally running a full-blown NN to estimate the accuracy of long-running smaller NNs
- Transfer learning includes retraining NNs on MCUs with data collected from deployment every hour or day
NN accelerators embedded in MCUs
Many of the challenges of implementing NNs on MCU are being addressed by MCUs with embedded NN accelerators. These advanced MCUs are an emerging device category that promises to provide designers with new opportunities to develop IoT node and edge ML solutions. For example, an MCU with a hardware-based embedded convolutional neural network (CNN) accelerator enables battery-powered applications to execute AI inferences while spending only microjoules of energy (Figure 2).
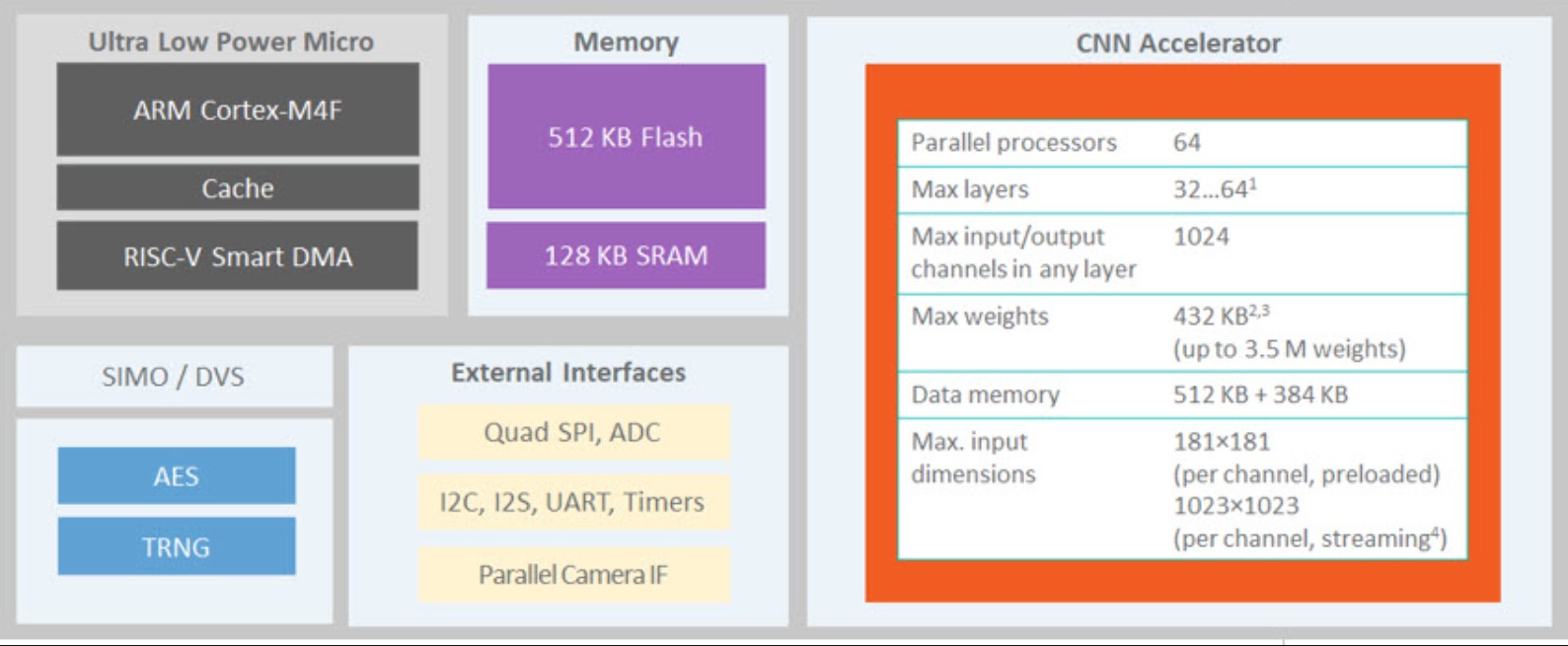
The MCU with an embedded CNN accelerator is a system on chip combining an Arm Cortex-M4 with a RISC-V core that can execute application and control codes as well as drive the CNN accelerator. The CNN engine has a weight storage memory of 442KB and can support 1-, 2-, 4-, and 8-bit weights (supporting networks of up to 3.5 million weights). On the fly, AI network updates are supported by the SRAM-based CNN weight memory structure. The architecture is flexible and allows CNNs to be trained using conventional toolsets such as PyTorch and TensorFlow.
Another MCU supplier has pre-announced developing a neural processing unit integrated with an ARM Cortex core. The new neural MCU is scheduled to ship later this year and will provide the same level of AI performance as a quad-core processor with an AI accelerator but at one-tenth the cost and one-twelfth the power consumption. Additional neural MCUs are expected to emerge in the near future.
Glow for smaller NN memories
Glow (graph lowering) is a machine learning compiler for neural network graphs. It’s available on Github and is designed to optimize the neural network graphs and generate code for various hardware devices. Two versions of Glow are available, one for Ahead of Time (AOT) and one for Just in Time (JIT) compilations. As the names suggest, AOT compilation is performed offline (ahead of time) and generates an object file (bundle) which is later linked with the application code, while JIT compilation is performed at runtime just before the model is executed.
MCUs are available that support AOT compilation using Glow. The compiler converts the neural networks into object files, which the user converts into a binary image for increased performance and a smaller memory footprint than a JIT (runtime) inference engine. In this case, Glow is used as a software back-end for the PyTorch machine learning framework and the ONNX model format (Figure 3).
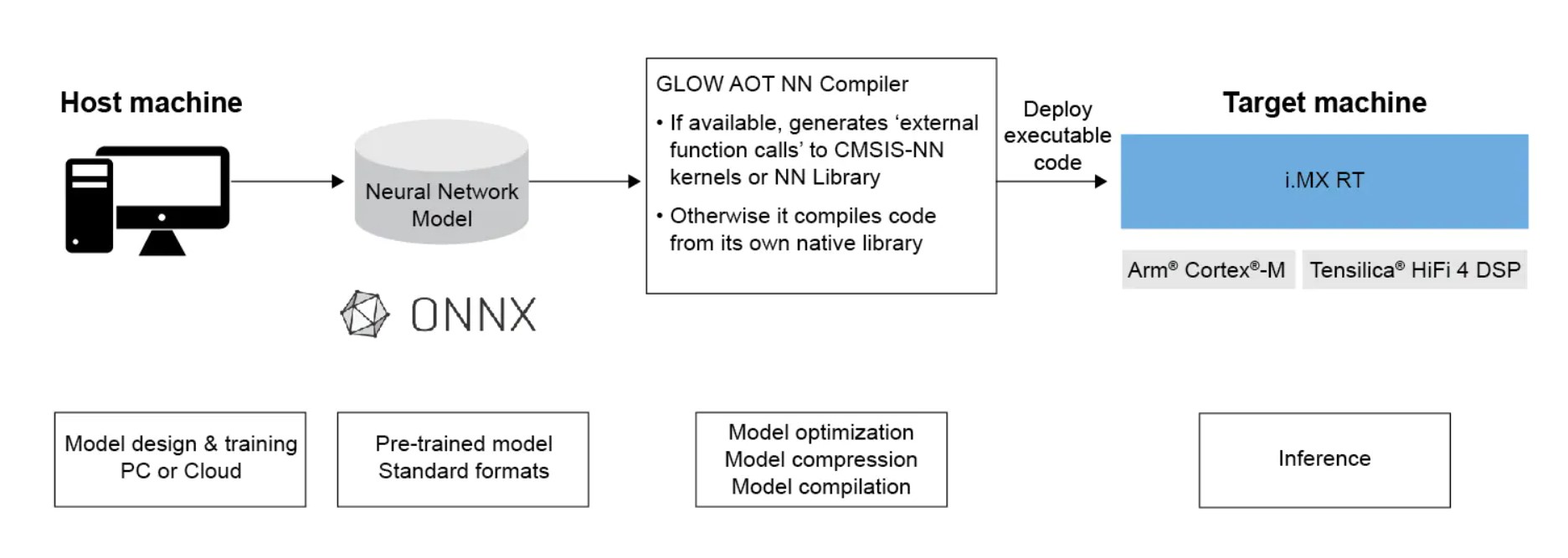
The Glow NN complier lowers a NN into a two-phase, strongly-typed intermediate representation. Domain-specific optimizations are performed in the first phase, while the second phase performs optimizations focused on specialized back-end hardware features. NNs on MCUs are available that combine support for Arm Cortex-M cores and Cadence Tensilica HiFi 4 DSP support, accelerating performance by utilizing Arm CMSIS-NN and HiFi NN libraries, respectively. Its features include:
- Lower latency and smaller solution size for edge inference NNs.
- Accelerate NN applications with CMSIS-NN and Cadence HiFi NN Library
- Speed time to market using the available software development kit
- Flexible implementation since Glow is open source with Apache License 2.0
Summary
Running NNs on MCUs is important for IoT nodes and other embedded edge applications, but it can be challenging due to MCU memory limitations. Several approaches have been developed to address memory limitations, including out-of-core designs that swap blocks of NN data between the MCU memory and an external memory and various NN software ‘optimization’ techniques. Unfortunately, these approaches involve tradeoffs between model accuracy and generality, which result in the NN becoming too inaccurate and/or too specialized to be of use in practical applications. The emergence of MCUs with integrated NN accelerators is beginning to address those concerns and enables the development of practical NN implementations for IoT and edge applications. Finally, the availability of the Glow NN compiler gives designers an additional tool for optimizing NN for smaller applications.
References
Artificial Intelligence Microcontroller with Ultra-Low-Power Convolutional Neural Network Accelerator, Maxim Integrated
eIQ® Inference with Glow NN, NXP
Enabling Large Neural Networks on Tiny Microcontrollers with Swapping, Arxiv
Glow, Meta AI