
By Pietro Antonio Ciclese, Senior Technical Marketing Engineer, Ambarella
The workloads that generate the most commercial value in edge AI scenarios run under power and thermal constraints that are, to put it mildly, very far from those found in data centers.
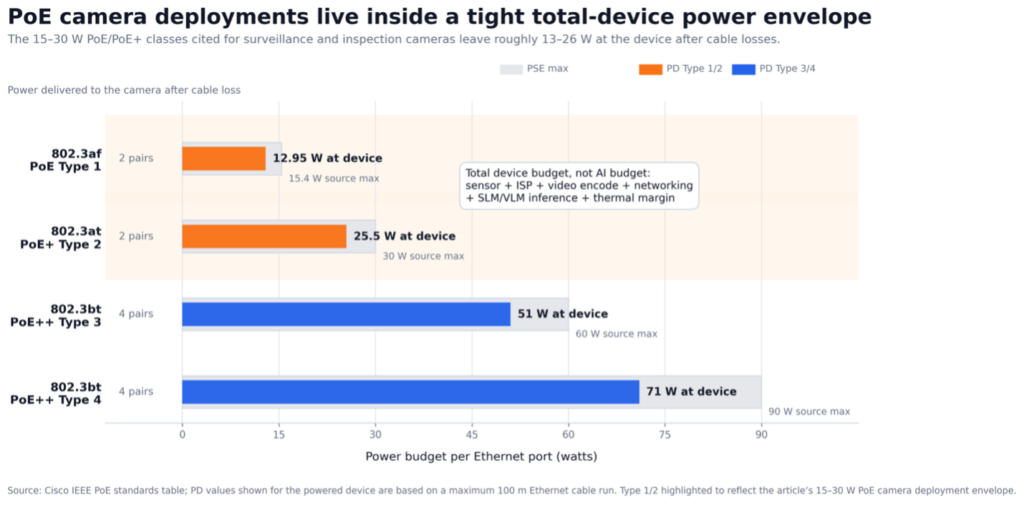
Take, for example, a vision camera used for surveillance or inspection. These often draw power over Ethernet, and are therefore capable only of delivering 15 to 30 watts in total. This power budget then must be divided between the image sensor, the ISP, the video encoder, and the network stack, meaning AI inference must run from what little is left.
Similarly, as they need to operate across a range of environmental conditions, it is not uncommon to see sealed modules, which limit thermal dissipation. Nor is it uncommon for them to have intermittent (or no) connectivity to an external server … but they still need to continue operations, in many cases needing to make pass/fail decisions in milliseconds.
The metrics for edge AI that govern deployment are very unlike those in data centers. They are instead: watts consumed per inference; the memory bandwidth available to the model; the latency from input to decision; and the total cost of ownership across the device fleet.
The cost of Cloud inference at device scale
Cloud pricing models work for sporadic, high-value queries, which compound when the workload is always-on across thousands of endpoints, but this is not the case for on-device inference. Instead, the marginal cost of each query is shifted to hardware and, after the initial silicon investment, the incremental cost per inference will be proportionate to the electricity consumed.
For example, Deloitte projects inference workloads will account for roughly two-thirds of all AI compute in 2026, and the inference-optimized chip market value will exceed $50 billion. The economic case for this shift is further reinforced by the industry’s need to manage availability, latency, and privacy. Relying on the cloud goes against all of these factors.
Even if connectivity is reliably available, using the cloud would add between 200 and 500 milliseconds of latency before the first token arrived, which disqualifies this approach for safety-critical perception, real-time inspection, and interactive voice applications. Further, as data leaves the device, privacy risks are created while in transit.
In comparison, a device running inference locally suffers none of these issues.
So, with cloud-based LLMs being inappropriate for edge use, are small models and processors up to the task? As a spoiler alert, the answer is yes!
Small models
Two major classes of edge models exist: near edge models, which will typically use up to 70 billion parameters; and far edge models, which use 8 billion or fewer – ideally around 4 billion.
Many of these models will implement a mixture of experts (MoE) architecture to balance high total parameters with efficient active parameters. For example, Meta’s Llama 4 Scout near-edge model uses 17 billion active parameters and 109 total. Other notable near-edge examples include Llama 4 Maverick and Qwen 3.5 / 3.6.
And for far edge systems, several sub-8-billion parameter models have been developed by the major model labs to specifically target edge hardware. These include Phi-4 mini, Llama 3.2, Qwen2.5, Gemma 3 and SmolLM2, with some of these even dropping into the hundreds of million parameters. [RA1]
At these levels, the architecture’s depth, training methodology, and data quality matter far more than scale, and this is especially true below c.1-billion parameters. Indeed, deeper, thinner networks have been shown to consistently outperform wide, shallow ones at equivalent parameter budgets. High-quality synthetic data, domain-targeted training mixes, and the distillation from larger teacher models will produce small models capable of outperforming ones several times their size on reasoning and task-completion benchmarks.
Additionally, there are compression techniques that further close the remaining deployment gap, and in particular quantization from 16-bit to 4-bit weights, which reduce memory traffic per token. As inference on edge hardware is both memory- and bandwidth-bound, that translates directly to throughput.

Speculative decoding, where a small draft model proposes multiple tokens and the target model verifies them in parallel, also delivers throughput improvements (in the region of 2-3X) without any additional hardware. And structured pruning removes entire attention heads or layers and runs efficiently on standard accelerator hardware. These techniques apply across modalities, and the same compression playbook works for vision-language models processing video alongside text.
Hardware constraints
Recent years have also seen huge advances in edge AI processing capabilities. To put this in context, today’s edge NPUs will deliver TOPS figures that are approaching performance from cutting edge devices used in data-center GPUs from 2017. This is more than enough to handle the smaller language models such as Llama 3.2. Instead, the binding constraint for autoregressive inference on edge devices is memory bandwidth.
It’s specifically for this reason that quantization has such a pronounced effect on real-world edge throughput: Generating each token requires the full model weights to be streamed through the processor, leaving compute units waiting for data. By moving from 16-bit to 4-bit, we reduce not only model storage but also memory traffic per token generated by a factor of four.
As we’ve touched on, thermal management and sustained power draw also impose hard limits. Clearly, a model that triggers thermal throttling in a sealed camera housing, or drains a drone’s battery during a 20-minute flight, will not be deployable regardless of its benchmark scores.
Similarly, space is a constraint on hardware, with devices rarely able to carry separate processors for each function. Therefore, when it comes to implementing edge AI silicon, the core requirement should be that neural network acceleration, image signal processing, and video encoding coexist on a single die within a fixed power envelope.

Where this is playing out
The above advances are playing out across a wide range of sectors. For example, in physical security, cameras are being deployed with vision-language models that can run within Power over Ethernet (PoE)’s tight power budgets.
These vision language models also shift the requirement for expertise in developing applications, with operators able to express their monitoring intent in natural language: count the people in a queue by passport control and give an alert if longer than X; or identify stranded bags on the station platform.
This is a huge step forward from the intensive and costly coding of custom, fixed-function analytics systems, as well as the multiple attempts to commoditize this through app store concepts that never really took off. And crucially, this shift to outcome-driven monitoring enables a marked reduction in per-site engineering cost that has historically limited AI adoption across large camera portfolios.
Elsewhere, these techniques can be adapted to industrial inspection, where vision-language models can be used to interpret defect images against natural-language quality criteria; as well as to automotive telematics and ADAS, where simultaneous convolutional neural networks (CNNs) and generative AI workloads are run on a single SoC inside a sealed module; as well as to drones, field robotics, and beyond.
The developer ecosystem
Of course, how well a model performs on a benchmark is not necessarily how it will perform when productized and shipped.
This gap is closed through tooling with model gardens that allow for model optimization to enable for specific silicon and the creation of pre-validated runtime packages with pre- and post-processing pipelines with reference workflows that reduce integration risk.
Furthermore, cloud-based benchmarking tools will also let independent software vendors test latency, power, and accuracy on target hardware before committing to a design. And agentic blueprints provide low-code templates for multi-agent workflows.
What comes next
It should be noted that the silicon vendors that capture this shift will be the ones providing the full path from model selection through optimization, testing, and production deployment. It will be these vendors, therefore, that reduce the engineering burden on software vendors and system integrators.
Extrapolating into the future, we’ve seen that the convergence of efficient models, specialized silicon, and developer tooling is compressing the distance between proof-of-concept and production deployment for edge AI applications across many vertical markets. And the huge improvements that have been seen in compact models will continue, allowing great leaps even with fixed compute budgets. As such, it’s clear that the range of workloads that can move from the cloud to the device will continue to expand.
It is already the case that successful scaling of edge AI does not need to mirror data-center capabilities but instead can still thrive within the unique constraints that are inherent to edge systems. And today’s SLMs, coupled with dedicated SoCs, already enable this. And as these silicon and software continue to advance, the boundary of what is deployable will continue to push further into the physical world, making autonomous, low-latency intelligence the default standard.