Tools like neural networks (NNs), machine learning (ML), and artificial intelligence (AI) are being applied to hard problems related to immersive audio.
This FAQ will examine how NNs and ML are being used to up-mix audio tracks into their original constituent parts, how NNs are being used to produce personalized head-related transfer functions (HRTFs) and looks at the European SONICOM project that aims to employ AI to produce personalized HRTFs for use in virtual-reality and artificial-reality (VR/AR) environments.
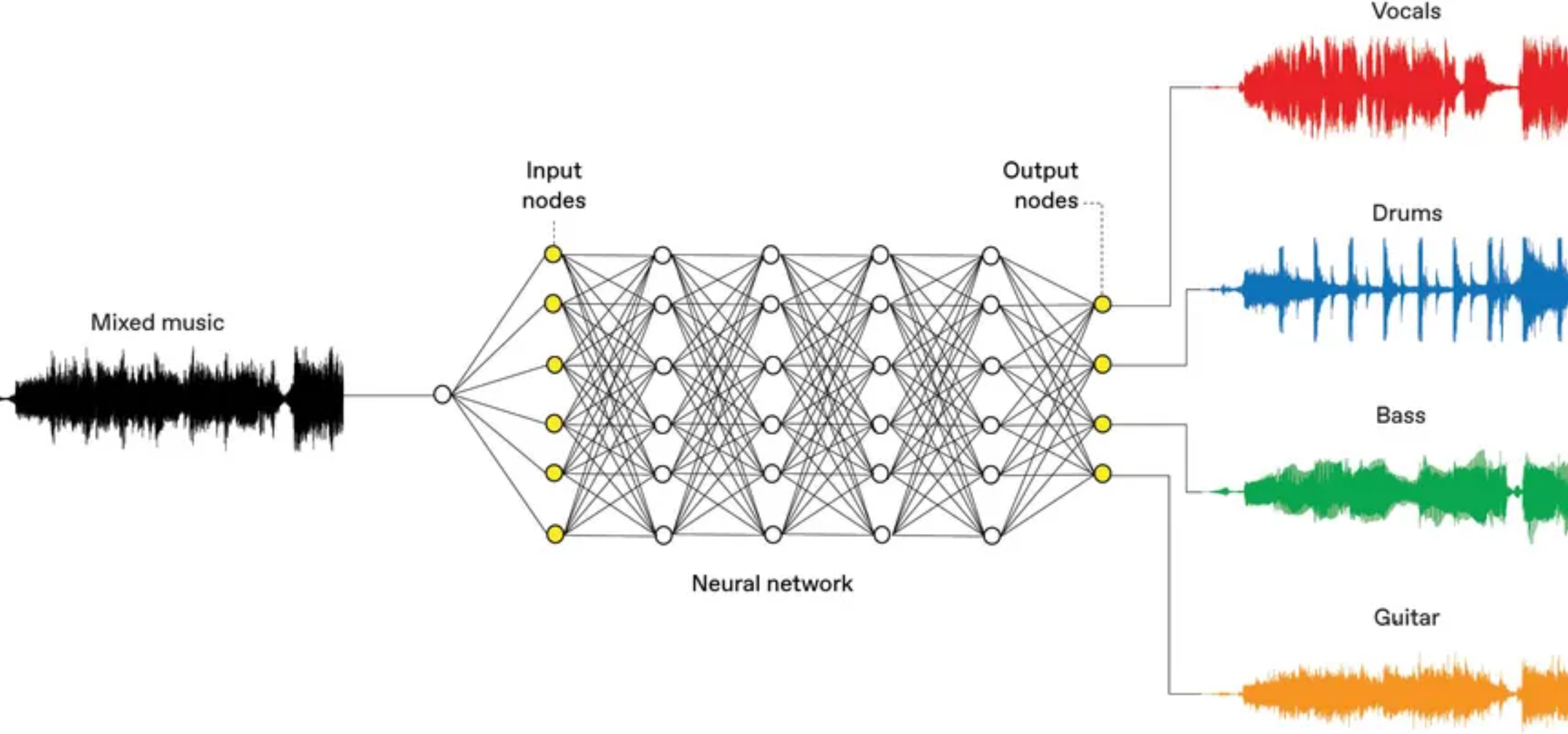
A software package called 3D Soundstage relies on deep-learning software running on a neural network to up-mix audio tracks. Up-mixing refers to the process of splitting audio tracks into a larger number of tracks that can be used for channel-based or object-based audio processing. 3D Soundstage is implemented in two steps: training followed by up-mixing.
During training, the software uses deep-learning software on a neural network with dozens of layers. The tracks move through the neural network, where they are gradually separated and sent to the output. The output is compared with the expected output, and machine learning is used to adjust the neural network parameters to improve the accuracy of the output.
Training this NN involved the use of tens of thousands of songs plus their separated tracks and took thousands of hours of processing. Training is iterative and continues until the output matches the expected result. At that point, the NN was ready to use for up-mixing (Figure 1).
HRTFs, HRIRs and MLP ANNs
In another application of NNs, a research team used a multilayer perceptron artificial neural network (MLP ANN) to generate personalized HRTFs and head-related impulse responses HRIRs. HRTFs are in the frequency domain, while HRIRs are the corresponding function in the time domain. An MLP ANN is a feedforward single-hidden-layer neural network.
A group of 17 pinnae (outer ear structures), with 1,671,865 instances, was the training data set used to build the models. Two pinnae, with 196,690 instances, were used for the testing dataset to evaluate the predictive ability of the models. Finally, the standard KEMAR pinna, with 98,345 instances, was used to validate the selected models. The KEMAR pinna meets the requirements of ANSI S3.36/ASA58-2012 and IEC 60318-7:2011 and is based on the global average male and female head and torso dimensions. Model validation focused on analyzing how predicted HRTFs improved the sound experience that can be obtained using the information of the standard pinna. The resulting MLP ANN was able to predict HRTFs with relatively low errors for new individuals using basic personal morphological features.

SONICOM
The SONICOM project seeks to develop a data-driven approach that uses AI for HRTF personalization. It expects to develop accurate HRTF models that combine minimal data related to ear morphology and listener preferences. The project uses a combination of parametric pinna model (PPM) HRTF development using AI and is exploring the possibility of using AI to pair new individuals with high-quality HRTFs in a database for a higher-quality result. The acoustic simulations are being validated using acoustic measurements (Figure 2).
The SONICOM project will also dig into using AI to blend virtual objects (and related sounds) into a larger VR/AR environment. One key will be to develop techniques for rapidly estimating the reverberant characteristics of the environment. The project expects to use AI to extract data about the acoustic environment surrounding the VR/AR user to produce a realistic, immersive experience. The team expects to use geometrical acoustics and computational models like scattering delay networks to produce real-time simulations of the listener’s environment.
Summary
NNs, ML, and AI are being applied to a variety of uses in audio processing. NN plus ML is being used for up-mixing single audio tracks to support more information tracks and enable channel-based or object-based audio processing. ANNs, AI, and ML are being used to develop techniques for rapidly producing personalized HRTFs for immersive audio processing. Some of those efforts are expected to be particularly attractive for use in AR and VR environments.
References
Deep learning could bring the concert experience home, IEEE Spectrum
Optimization of HRTF Models with Deep Learning, Mathworks
Prediction of Head Related Transfer Functions Using Machine Learning Approaches, MDPI acoustics
The SONICOM Project: Artificial Intelligence-Driven Immersive Audio, From Personalization to Modeling, IEEE
Spatial Audio Meets AI, Steinberg