There are many artificial neural network (ANN) architectures, each suited for specific tasks. This FAQ begins with a review of the components of the neurons that make up ANNs, looks at the basic elements of ANNs, and then presents the top architectures.
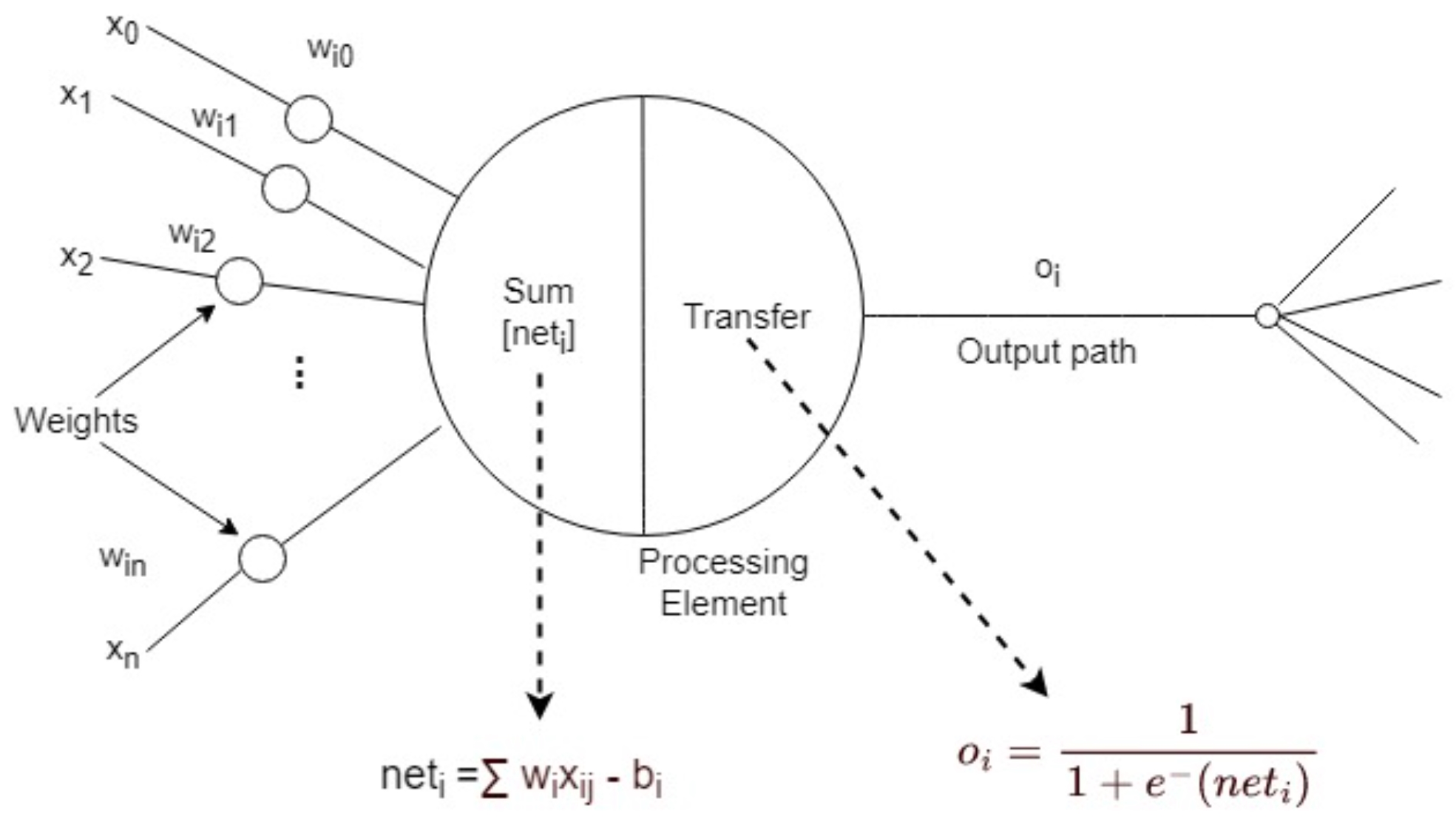
There are several forms of neurons with slightly different mathematical structures. Most neurons are comprised of four components (Figure 1).
- Inputs — The set of features used to train the network.
- Weights — Uses scalar multiplication between the input value and the weight to establish the relative importance of the features.
- Summation — A linear combination of all the inputs and corresponding weights into a single value that the transfer function can operate on. This can be a weighted average and can include a bias term to shift the value.
- Activation (Transfer) Function — Adds non-linearity, for example, a sigmoid function that accepts a linear input and gives a nonlinear output to account for the varying linearity of the inputs. The sigmoid is a mathematical function that maps input values to an output between 0 and 1.
ANN layers
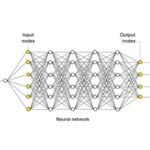
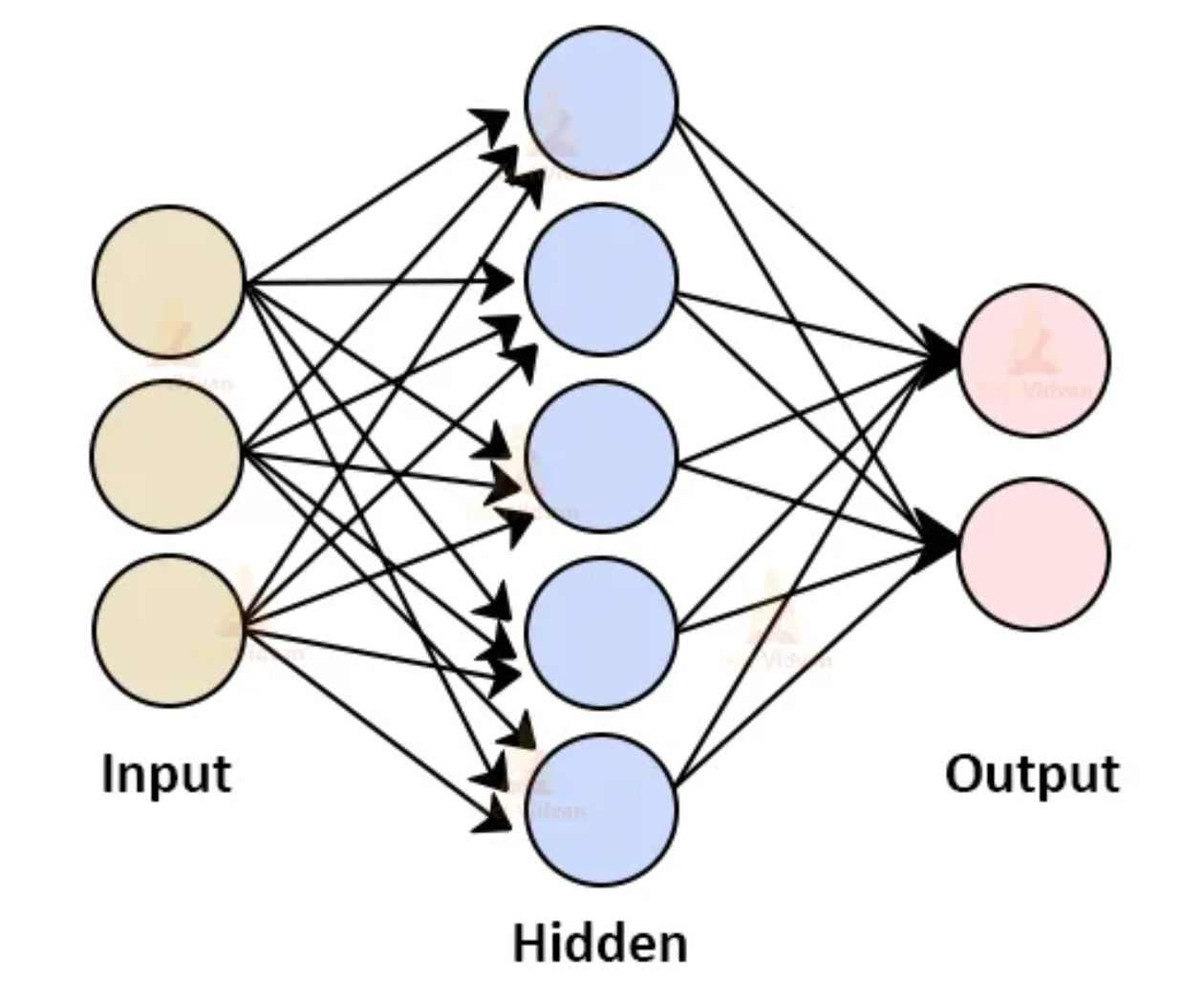
Most ANNs are built using three layers (Figure 2). The way the layers are structured and interconnected determines the ANN architecture.
Input Layer — neurons receive the inputs, process them through a mathematical function, and transmit output to the neurons in the first hidden layer based on comparison with preset threshold values.
Hidden Layer — neurons do the primary computations and extract features from the inputs. There will be one or more hidden layers. This is where machine learning happens. In ANNs with multiple hidden layers, the initial layers identify high-level features, like the edges in an image, and subsequent hidden layers perform more complex tasks, like identifying complete objects in an image.
Output Layer — takes the results from the final hidden layer. It’s usually a single layer and can be used as the result or as an input to a new loop in the same or a different ANN.
Top five ANN architectures
There’s a wide range of ANN architectures, and each one is suited for specific types of applications. Five of the most common include:
Perceptron is a supervised learning algorithm that classifies data into two categories. It’s also called a binary classifier. Binary classifiers are a fundamental building block of many ML applications. It accepts weighted inputs and applies the activation function to obtain the output as the result. They are only useful for linearly separable problems. A perceptron is a type of threshold logic unit (TLU). They can implement logic functions like AND, OR, or NAND.
Feedforward NN (FNN) is one of the two basic types of ANNs. FNNs are characterized by a uni-directional (forward only) flow of information between layers, in contrast to recurrent neural networks, which have a bi-directional flow. In FNNS, learning occurs by changing connection weights after each piece of data is processed based on the error in the output compared to the anticipated result. They can’t be used for deep learning since there is no backpropagation or dense layers.
Convolutional NN (CNN) is a type of FNN that’s suited for deep learning and used in applications like image, speech, and audio processing. They have three types of layers: convolutional, pooling, and fully connected. The convolutional layer is where most of the processing happens. There can be more than one convolutional layer, with additional layers used to identify higher-level patterns and features. The pooling layers, also known as downsampling, simplify the model by reducing the number of parameters in the input to improve model performance and efficiency. The fully connected layer completes the task of classification using the features extracted by the earlier layers.
Radial Basis Function NNs (RBF) are a class of FFN. In an RBF, the sigmoidal hidden layer transfer characteristic is replaced with a function that has a distance criterion with respect to a center. RBF NNs are fundamentally different from other types of NN. While most NNs have many layers, RBF NNs have only three layers, an input layer, a single hidden layer, and an output layer. The hidden layer often uses Gaussian transfer functions whose outputs are inversely proportional to the distance from the center of a neuron, but other radial bias functions can also be used, like multiquadric or inverse quadradic. RBF NNs are useful for approximating continuous functions like the movement of robotic arms.
Recurrent NN (RNN) is a bi-directional ANN that uses the output from some nodes to affect subsequent input to the same nodes. The first layer is usually an FFN, followed by one or more RNN layers. In the RNN layers, some information from a previous layer is stored in a memory function. If the prediction is wrong, the learning rate makes small changes, gradually moving the prediction toward the correct result (with smaller errors) using backpropagation. RNNs are used for deep learning in natural language processing, speech recognition, and similar applications.
Summary
ANNs are made up of neurons that process information in precise ways. Most ANNs consist of an input layer of neurons, one or more hidden layers, and an output layer. The various ANN architectures are distinguished by the way the layers are connected, by the direction or directions the data travels through the layers, and by the mathematical functions implemented by the neurons.
References
Architecture of Artificial Neural Network, Knoldus
Neurons in neural networks, Baeldung
The Essential Guide to Neural Network Architectures, V7 Labs
Types of Neural Networks and Definition of Neural Network, Great Learning
What Is Neural Network Architecture?, H2Oai